
Grafbase provides an edge-native GraphQL platform that combines multiple data-sources into a single API and includes a serverless database, search, edge caching, preview environments and much more. Around May 2022 we started working on a local development experience, written in Rust, to mirror this functionality locally and allow you to interact with our product from your terminal. We wanted to emphasize good developer experience and create a robust solution that was simultaneously performant, feature rich, convenient and easy to use. The following is an overview of various aspects of that experience.
Rust is a fast-growing and versatile language that focuses on efficiency, reliability and productivity. It beautifully combines the bare-metal performance of languages like C or C++ with the flexibility, richness and correctness of languages like the ML family or Haskell. Its tooling is a pleasure to use, it is constantly and predictably updated, and the Rust Project allows the community to influence and contribute to the language. For all the reasons above and (many) more, we truly love using Rust at Grafbase.
As Grafbase already uses Rust compiled to WebAssembly for our user-generated and internal APIs on the Cloudflare Workers platform, using Rust in our CLI (command line interface) as well allows us to re-use code between the two and allows our entire backend team to contribute to the CLI without any friction.
CLIs written in Rust provide near instant start times and enjoy the great ecosystem of crates (Rust libraries) specifically targeting CLIs, like clap which greatly simplifies the process of argument processing and automatic generation of help output and completions.
For example, defining a set of subcommands with clap is as easy as defining structs and enums. Documentation comments (///) are used as the help output, and tuple variants can be defined for subcommands requiring flags or arguments:
use clap::Parser;
#[derive(Debug, Parser)]
#[command(name = "Grafbase CLI", version)]
/// The Grafbase command line interface
pub struct Args {
/// Set the tracing level
#[arg(short, long, default_value_t = 0)]
pub trace: u16,
#[command(subcommand)]
pub command: SubCommand,
/// An optional replacement path for the home directory
#[arg(long)]
pub home: Option<PathBuf>,
}
#[derive(Debug, Parser)]
pub enum SubCommand {
/// Run your Grafbase project locally
Dev(DevCommand),
/// Output completions for the chosen shell. To use, write the output to the
/// appropriate location for your shell
Completions(CompletionsCommand),
/// Set up the current or a new project for Grafbase
Init(InitCommand),
/// Reset the local database for the current project
Reset,
/// Log into your Grafbase account
Login,
/// Log out of your Grafbase account
Logout,
/// Set up and deploy a new project
Create(CreateCommand),
/// Deploy your project
Deploy,
/// Connect a local project to a remote project
Link,
/// Disconnect a local project from a remote project
Unlink,
}
const DEFAULT_PORT: u16 = 4000;
#[derive(Debug, Parser)]
pub struct DevCommand {
/// Use a specific port
#[arg(short, long, default_value_t = DEFAULT_PORT)]
pub port: u16,
/// If a given port is unavailable, search for another
#[arg(short, long)]
pub search: bool,
/// Do not listen for schema changes and reload
#[arg(long)]
pub disable_watch: bool,
}
// ... other subcommand argument definitions ...
let args = Args::parse();
// `args` now contains the user subcommand and flagsAs we provide preview environments, you may wonder why we find it important to allow users to test and develop locally. Local development has a much shorter feedback loop, which allows developers to quickly test changes and work more efficiently without needing to wait for external, remote processes like deployments or continuous integration. When using the CLI, you’re limited only by the speed of any external resources you call, and if you’re only using our provided database and / or local services you can run completely offline¹.
Our CLI also allows you to run remote operations, for example deploying a project from your terminal or CI (continuous integration), to best fit into your normal workflow and tooling.
When initially designing the CLI it was important to us that we provide an experience requiring the minimum amount of configuration, and outside of requiring Node.js for various flows (which you’ve likely used to install the CLI to begin with) we require zero external dependencies. We didn’t want users to need to wrestle with Docker or the JVM (Java Virtual Machine) to be able to start working, and the result is a clean and simple npx grafbase <COMMAND> to hit the ground running.
¹Our playground, Pathfinder, is currently provided via CDN
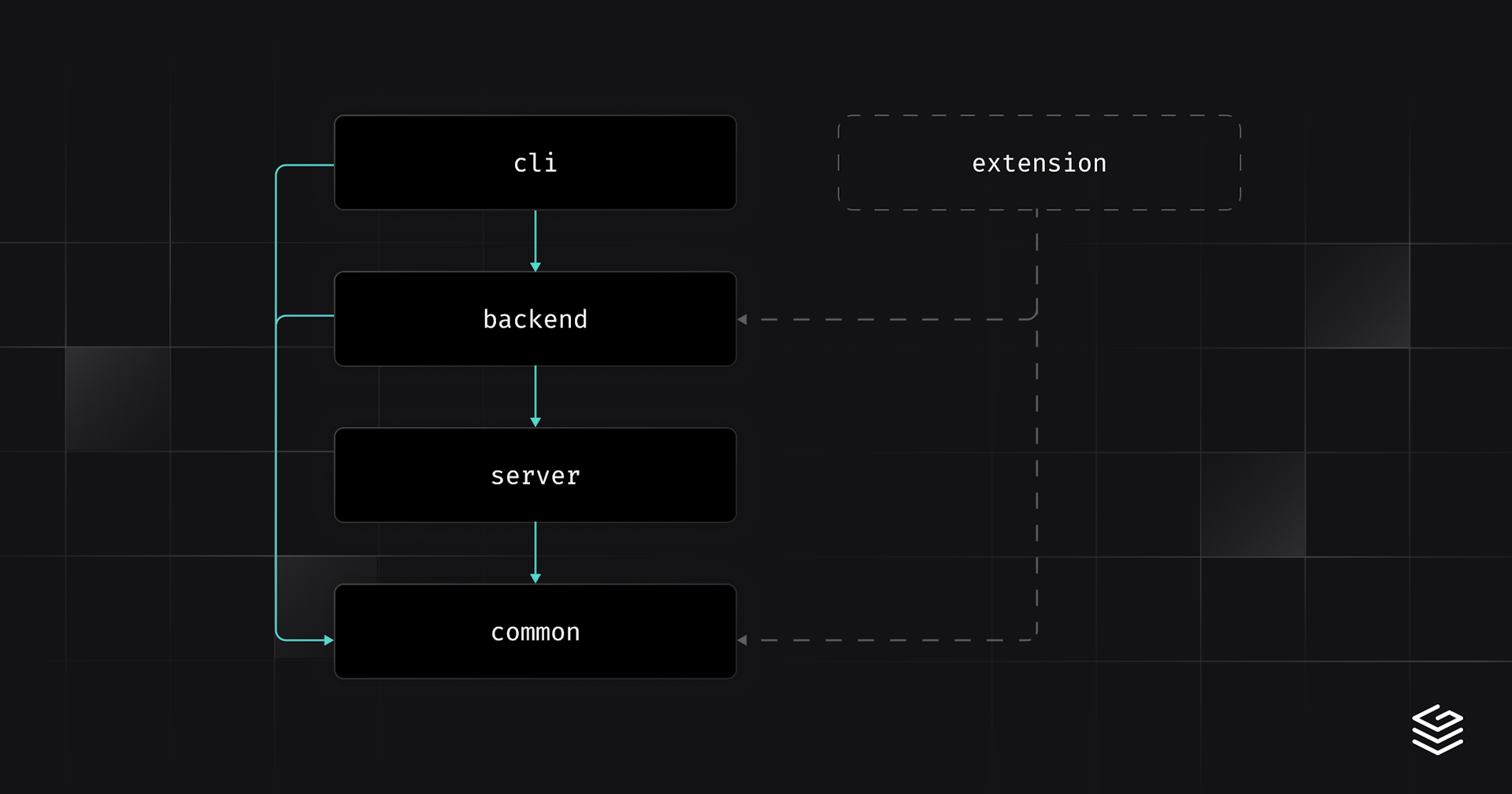
Our local development experience is split into multiple crates in the following structure:
grafbase(cli) - A thin front end, handling the CLI arguments, input and outputbackend- The core logic of the local development experience, communicates with our internal API. Wraps the functionality provided byserverserver- Logic related to the development server and SQLite, wrapsminiflarecommon- Shared data and functionality, e.g. current environment and project data
This structure allows us to plug and play new front ends for the local development experience by connecting them to functionality from backend, which is front end agnostic (rather than being directly coupled to the CLI environment for example) e.g. a future IDE extension.
As our user-generated API is compiled to WebAssembly and was originally closed-source (this will change soon, stay tuned), we use miniflare (an open-source project that simulates the Cloudflare Workers production environment) to run the generated API locally within the CLI. At build time, various pre-compiled WebAssembly files and Node.js modules are compressed and embedded within our CLI binary, to be extracted on the first run of the dev command. This means that when debugging locally you’re essentially running the same code as production (compiled with a few different features, see below), which minimizes incompatibilities or issues found only after deploying.
Although our production database offering is built on DynamoDB, we wanted to avoid requiring DynamoDB Local (which is Java based and would require a JVM install or Docker) to simulate a deployed database. To this end we compile our production worker with an sqlite flag which switches out the layer interfacing with DynamoDB with equivalent functionality built around SQLite (which is similar to the storage method employed by DynamoDB Local). This switch is made possible by translating queries and mutations into discrete database operations (e.g. InsertNode, UpdateNode) which are then implemented both for DynamoDB and SQLite. As WebAssembly (and by extension our Cloudflare Workers) does not have filesystem access, we expose a server we call the “bridge” server from the CLI which the worker running in miniflare communicates with via HTTP, sending SQL queries and metadata. The bridge server in turn can speak with SQLite directly.
Our local database uses single-table design (for normal data storage), and has a schema that consists of columns which reflect our own “system” data (which we set automatically, e.g. primary keys, secondary keys, creation and update times) and two JSON columns, one to store user data (which also copies the system data for ease of use) and the other for relation data. This split lets us query our system data using known access patterns while still allowing querying and manipulating user data without prior knowledge of its structure / needing separate tables for separate data types. This configuration also allows us to set the same constraints that DynamoDB uses, which keeps any invariants we rely on intact locally.
DynamoDB has an update stream mechanism that we employ for our Live Queries feature, which we simulate locally via SQLite triggers. The triggers update a separate table on every mutation, which is polled on an interval (as DynamoDB updates are also received in intervals, this retains the same external behavior). On each polling pass any collected events are deleted from the table to prevent duplications or “phantom events” on the next CLI run.
We use Tantivy (an OSS full-text search written in Rust) locally and in production for our Serverless Search functionality, more details on search in an upcoming post.
We distribute the CLI on NPM using a method inspired by moonrepo and Parcel. This method involves distributing one NPM module per supported arch including a binary, and a main NPM module that requires them as optional dependencies. The main module includes a binary placeholder and a postinstall.js script which requires and links or copies the correct binary for your platform from one of the modules, making the install transparent for users while still using native code.
The CLI is also distributed in binary form on GitHub releases.
We take a page out of the Rust compiler philosophy by attempting to have errors that are as specific as possible and defining hints for failure scenarios that can be rectified by the user. All errors across our crates are defined with the thiserror crate as enum variants, and in turn the front end crate (e.g. cli) defines hints for various errors to allow customization depending on how the user is accessing the local development experience (what happened is normally constant, how to fix it can depend on the context). These errors include scenarios like file permission issues, corrupt files, running the CLI in invalid contexts (e.g. with an unsupported version of Node.js or running a command that requires a project outside of a project directory) and more. We print an error in each of these cases, a relevant sub-error if one exists (e.g. an io::Error), and in many cases include a helpful hint to guide the user to a possible resolution of the issue.


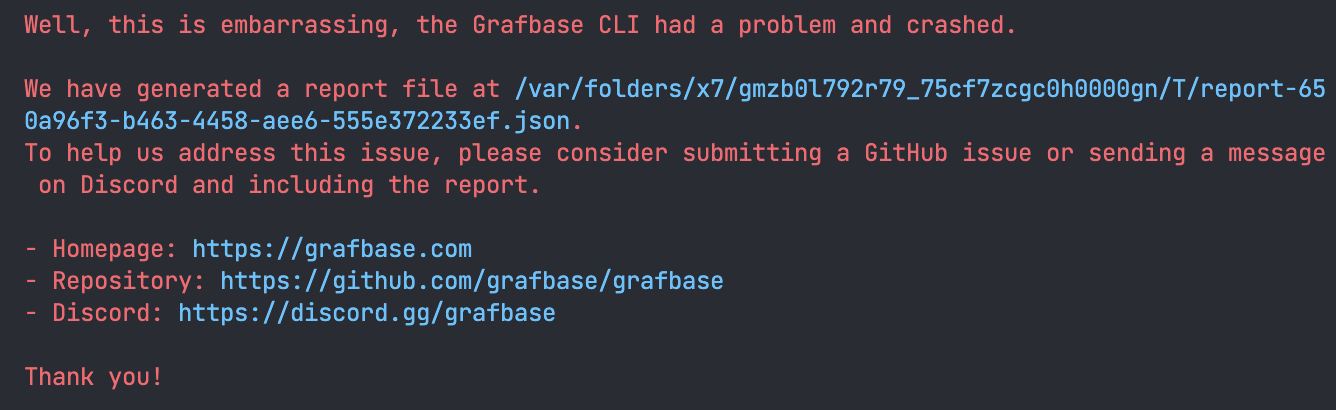
If the error is a non-user-serviceable error (a logic error / bug), we display a human formatted panic message (via a fork of human-panic) and create a report that users can then submit to us.
In this post we’ve detailed some of the building blocks and considerations that went into creating our local development experience.
We’re always working on improvements and new features, and there’s much more on the horizon!
Star our public GitHub repository, join our Discord, and follow the changelog to keep up with new releases. Any feedback or suggestions are always welcome!